I am currently building a RAG (Retrieval Augmented Generation) LLM application, and recently
decided to share my journey on this blog.
I skip the intro and jump straight to my current status. Here’s where I am:
- Starting Point: To get started with all the boilerplate code, I used the Metaflow RAG demo repository and this anyScale blog post for insights and second point of view. Metaflow’s repo include a streamlit chat webapp, utilities for scraping and parsing markdown documentation files, etc.
Current Status
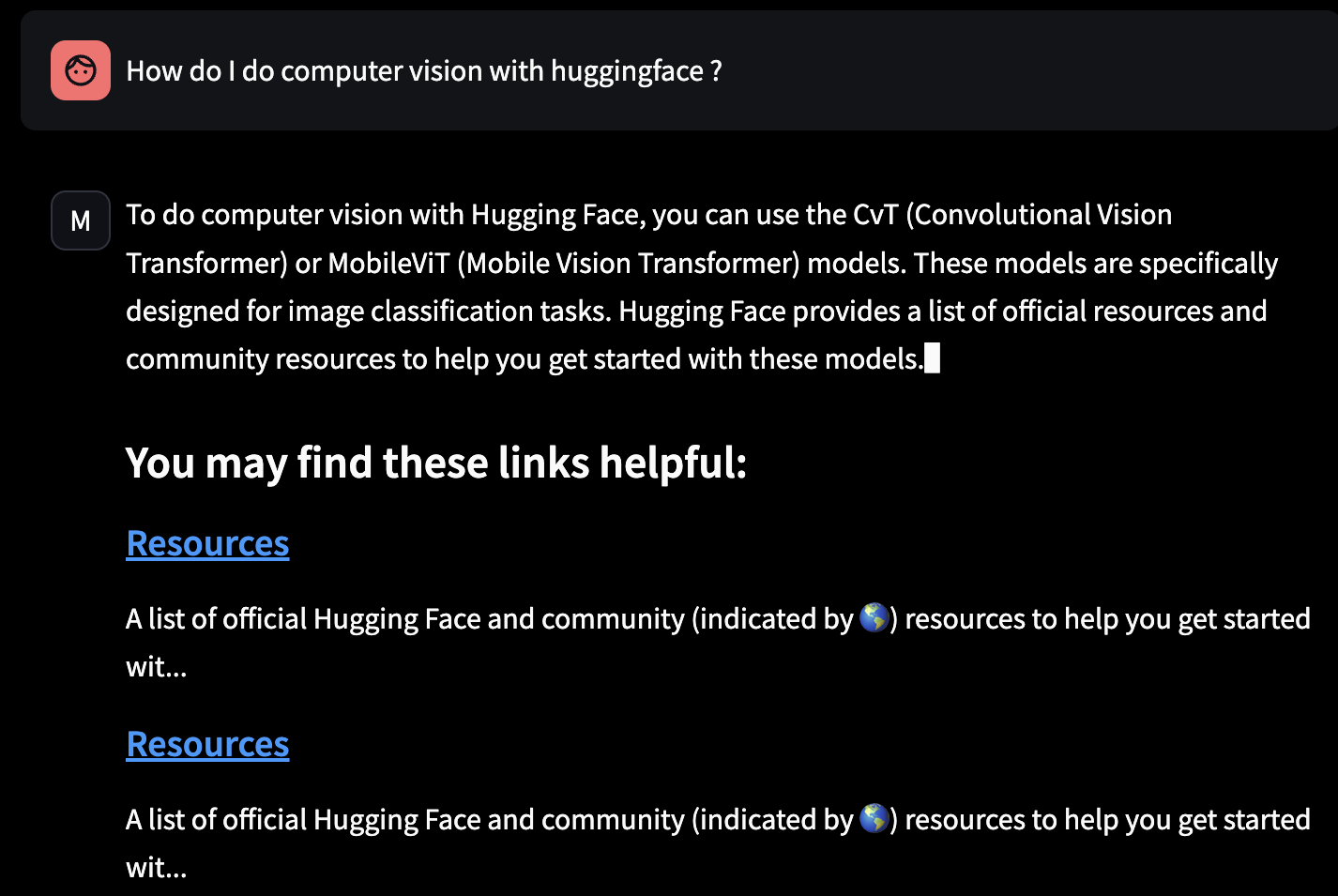
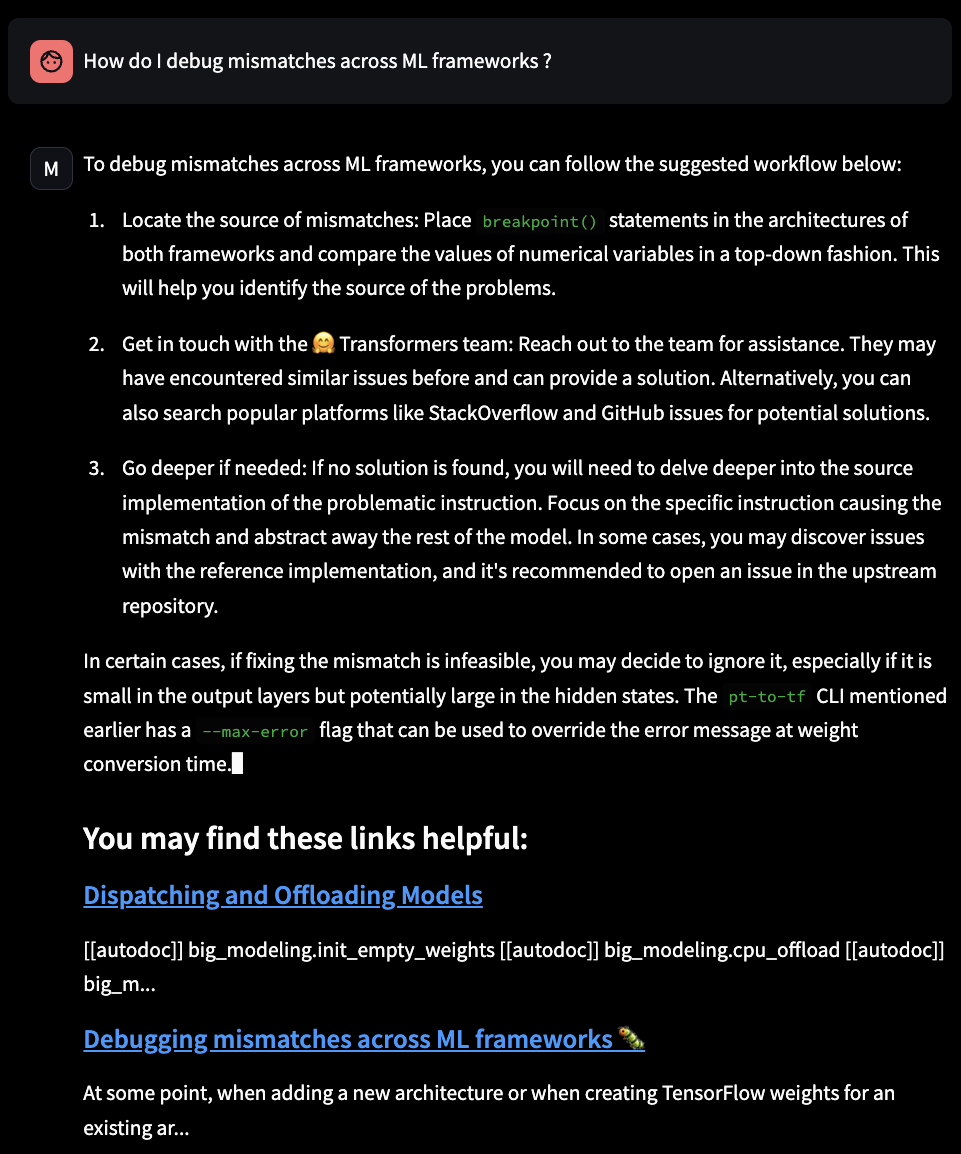
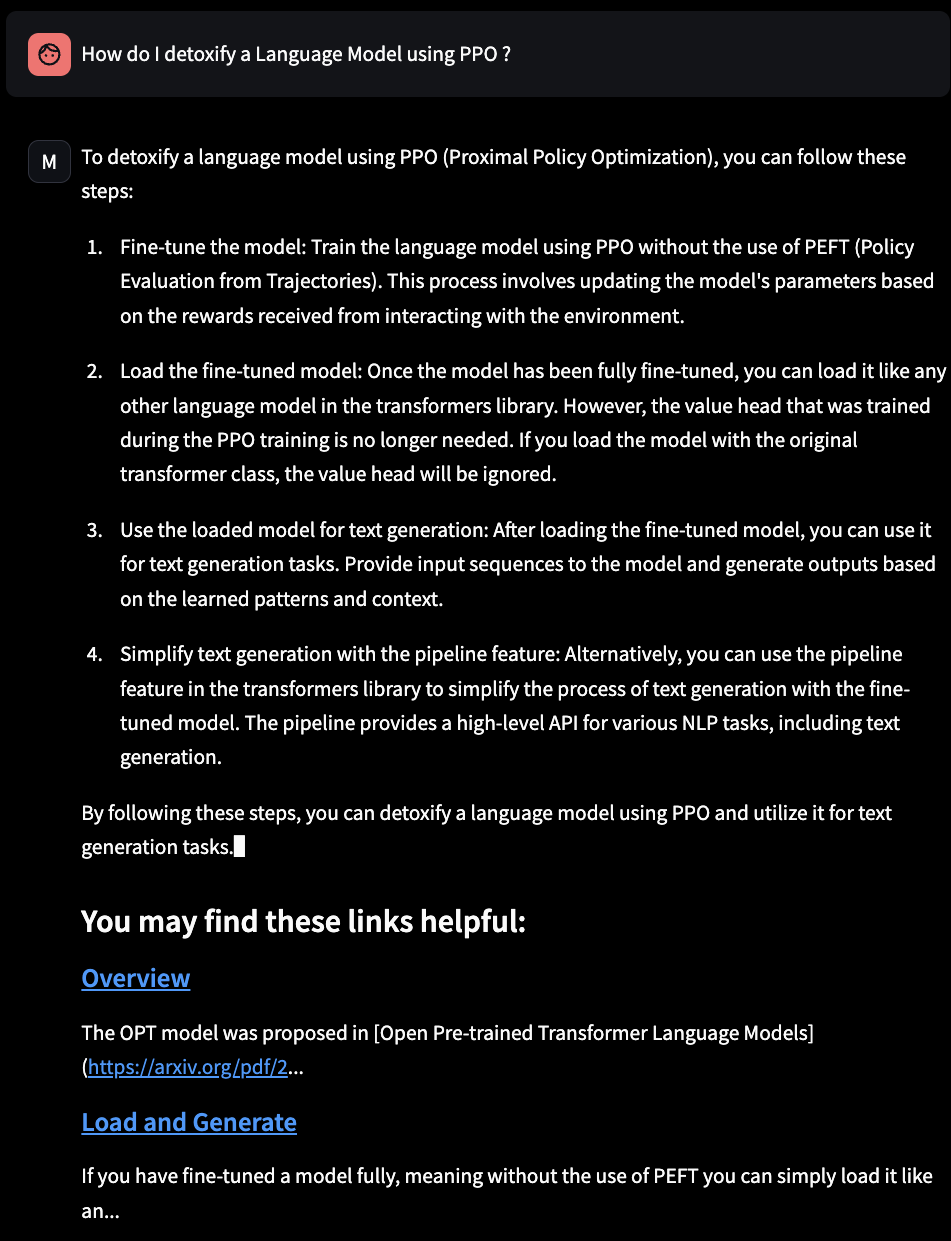
- I replicated what was done on Metaflow’s blog, augmented with Metaflow’s docs. Now, I want to do one with Hugging Face’s docs as well, focusing on three libraries: transformers, accelerate, TRL (Transfer Reinforcement Learning).
- It works, but, it’s not amazing for now :
Make iteration cycles cheap
Currently, the pipeline uses openAI text-embedding-ada-002 (default from LLamaIndex) API for embeddings.
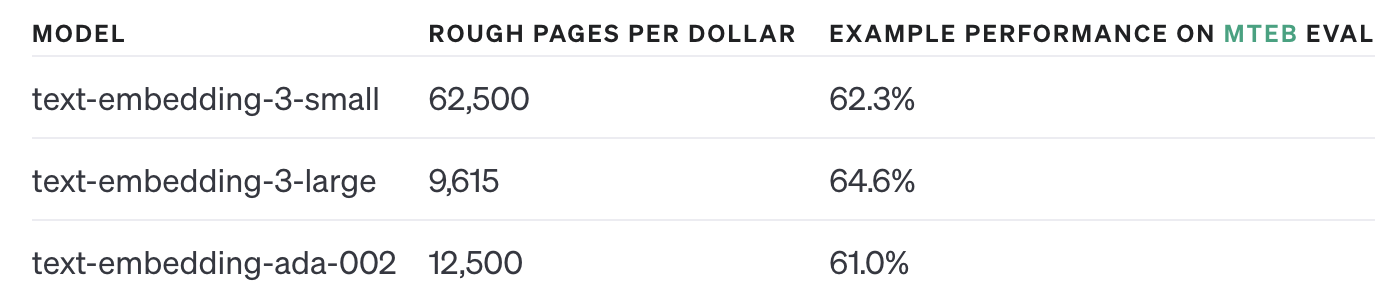
As you can see, there is now a text-embedding-3-small by OpenAI. It’s about 1/10th of the price, and is
more performant : double win. Let’s use it :
from llama_index import ServiceContext, set_global_service_context
from llama_index.llms import OpenAI
ServiceContext.from_defaults(llm="gpt-3.5-turbo", embed_model=OpenAIEmbedding(model='text-embedding-3-small'))
set_global_service_context(service_context)
You can also choose any HuggingFace’s model to do the embeddings locally on your computer. One of the best
at the time of writing is BAAI/bge-large-en-v1.5. You must tell LLamaIndex that it’s gonna be a local model with local: :
ServiceContext.from_defaults(llm="gpt-3.5-turbo", embed_model='local:BAAI/bge-large-en-v1.5')
I kept the LLM as GPT-3.5 for now, as it’s cheaper, and I’m mostly testing the relevance of the context augmentation at this stage, not the model itself.
While doing this modification, I found the prompt used in the initial RAG repo.
Prompt modification
It’s the prompt used to include the context from the vectorDB, and then ask the question to the LLM :
prompt = """
Answer this question only if there is relevant context below: {}
If there is nothing in the context say: "Could not find relevant context."
Here is the retrieved context: {}
"""
I changed it to make it more flexible, I think it will help me in debugging and evaluating the pipeline.
prompt = """
Answer this question using your existing knowledge the relevant context below: {}
If the context doesn't help you answer, prefix your message with: "Context not relevant."
If the context is empty, prefix your message with: "No context."
If you don't know the answer and the context doesn't help you, say "I don't know".
Here is the retrieved context: {}
"""
It actually helped me later, I found out randomly that my context retrieval wasn’t working so good 😂 (or that I trained on the
wrong data) :
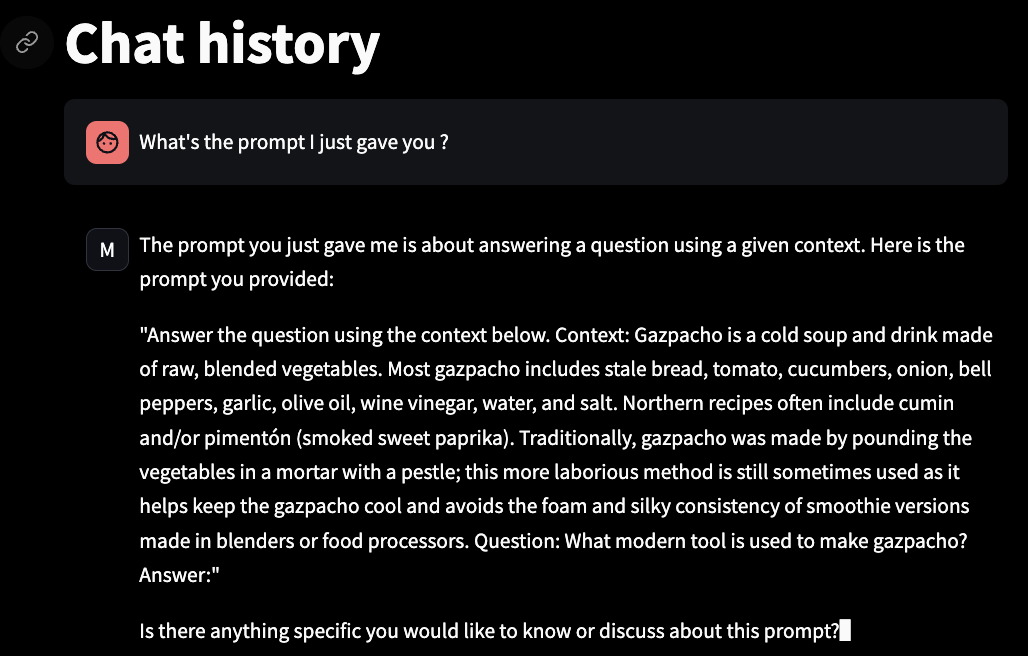 Found in HF docs :
Found in HF docs :

Next Steps
- Check if embeddings are saved between runs and see what’s the default strategy when iterating on the pipeline
- Run metaflow UI locally to easily track experiments
- Consider switching to a proper vectorDB
See you for day 2 !