Now that I have a basic RAG working, I performed a few experiments to assess its accuracy in retrieving relevant documents.
I did an experiment where I took one part of huggingface TRL library that is supposed to be included in my embeddings, regarding DPO (Direct Preference Optimization) :

Then, I asked my model questions about it, but it wouldn’t get them right, and outputted something like chatGPT would, without context and knowledge about DPO.
At this moment, I figured out I am probably going to perform multiple experiments : adjusting the filters, parsing techniques, etc, so I figured I will need a good tool to track the experiments, quickly retrieve the artifacts, etc. I used code from metaflow so my pipeline was already structured as a Metaflow flow, but I didn’t have the associated services required to fully enjoy the features.
Time to deploy Metaflow service, DB and UI locally with docker so that we can easily push it to the cloud if I need it at some point.
Deploy metaflow
To run the metaflow service (which includes one docker for metadata and one for UI backend) :
git clone https://github.com/Netflix/metaflow-service.git && cd metaflow-service
docker-compose -f docker-compose.development.yml up
It runs on the 8083 port by default.
Now run the metaflow UI front-end, using the endpoint of your just deployed service :
git clone https://github.com/Netflix/metaflow-ui/ && cd metaflow-ui
docker build --tag metaflow-ui:latest .
docker run -p 3000:3000 -e METAFLOW_SERVICE=http://localhost:8083/ metaflow-ui:latest
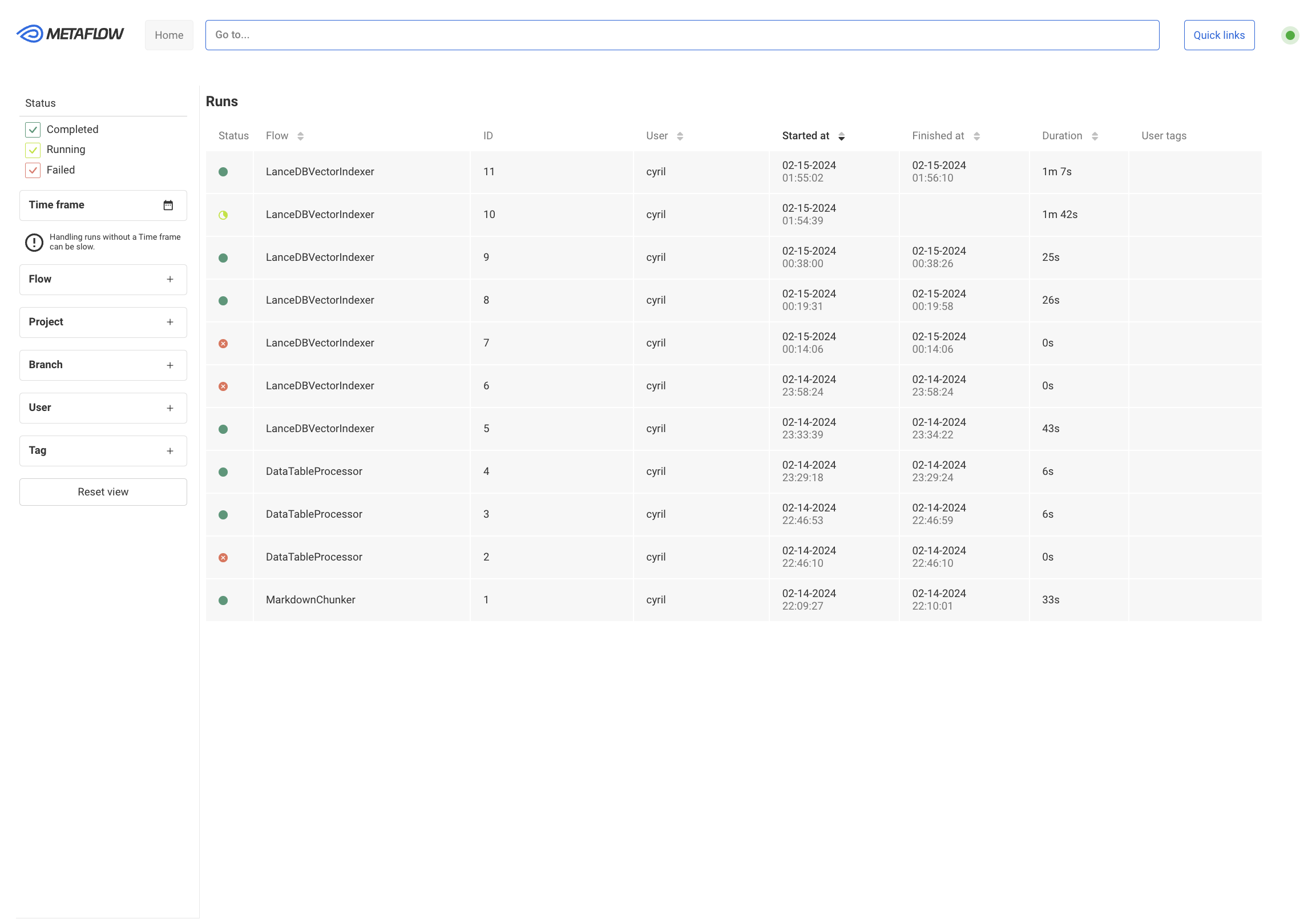
It works 🥳
Now,I can easily visualize my runs, and if I saved some artifacts during my flow with self.my_df = my_df like :
@schedule(daily=True)
class MarkdownChunker(FlowSpec):
@step
def parse_clean_docs(self):
self.repo_params = config.repo_params.MARKDOWN_REPOS_TO_INDEX
self.parsed_filtered_df = self.pre_process_markdown()
self.next(self.end)
Now, I can eventually inspect one run’s artifacts in a notebook :
from metaflow import Flow
flow = Flow("MarkdownChunker")
run = flow.latest_successful_run
parsed_filtered_df_latest_run = run.data.parsed_filtered_df
So, parsed_filtered_df_latest_run is the dataframe of the parsed, clean content to be retrieved
in the RAG app. I inspected it and noticed that the DPO part I was looking for, is not in the dataframe,
so it was either filtered out, or not scraped at all, so it won’t exist in the embedding’s DB and can’t be
fed as context to the LLM.
I now need to iterate on the parsing/filtering logic before embeddings, and figured out it was a good time to configure a proper Vector DB, and use LLamaIndex as an abstraction of the interface between my content and the DB.
Setup LanceDB
I wanted to persist my embeddings so that they are not recomputed each time (it takes CPU/GPU time if done locally, money if done with openAI’s embedding)
For now it was persisted on the disk by default, but I want to switch to a proper vector DB :
- more efficient for querying
- closer to a production setup
I heard from my friend in ML that lanceDB was currently a great choice (open-source, very efficient (written in Rust), easy to use), but if you need to do it yourself, I suggest comparing the available solutions yourself. Here’s a helpful pdf to help you in this task.
Here is how to do it :
Create the Vector DB
vector_store = LanceDBVectorStore(uri="./data_lanceDB") # Switch to a
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_vector_store(
vector_store, storage_context=storage_context
)
Embed your data and insert it in the vector store
# Get the latest execution of our markdown processing pipeline with metaflow
for _run in Flow('DataTableProcessor'):
if _run.data.save_processed_df:
run = _run
break
df = run.data.processed_df
vector_store = LanceDBVectorStore(uri="./data_lanceDB")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
[Document(t) for t in df.contents], storage_context=storage_context,
)
Under the hood, the last instruction actually embeds our data using the previously defined service_context (See
part 1 of this blog series), if
defined globally (set_global_service_context(service_context)), or you can also pass it
as a service_context=service_context parameter of the VectorStoreIndex.from_documents().
Retrieve your existing embeddings
def load_index():
vector_store = LanceDBVectorStore(uri="./data_lanceDB")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_vector_store(
vector_store, storage_context=storage_context
)
return index
Now that our pipeline is set to use Metaflow, we can save the index (our custom data vectorized in LanceDB)
during the flow with self.embeddings_index = index to access it later, at inference time for instance.
You can then use it to perform simple retrievals :
retriever = self.embeddings_index.as_retriever(similarity_top_k=5)
query = "How do I fine-tune a model with HuggingFace DPO ?"
retrieved_nodes = retriever.retrieve(query)
retrieved_context = [node.get_text() for node in retrieved_nodes]
print(f"Retrieved context associated with query '{query}' : \n{retrieved_context}")
Or as a query engine, which will fetch the relevant prompt from our query, and embed it with our query to ask a LLM (any LLM can be configured : openAI, local, Ollama, API, Groq…) :
from llama_index.llms.huggingface import HuggingFaceLLM
llm = HuggingFaceLLM(model_name="HuggingFaceH4/zephyr-7b-alpha")
query_engine = self.embeddings_index.as_query_engine(service_context=ServiceContext.from_defaults(llm=llm))
response = query_engine.query(query)
print(f"Response from model for query {query} : \n{response.response}")
Or as a chat engine, which can handle context and history :
index.as_chat_engine(
chat_mode="condense_plus_context"
context_prompt="...Use your personal knowledge AND the context retrieved here {context_str}"
)
Various chat modes exist in LlamaIndex, depending on if you want context or not, how to deal with chat history, etc.
Note: In some usecases you’ll want to fully disable the LLM’s knowledge, and force it to only use the context, to avoid hallucinations for instance.
Next Steps
- Check how the default prompt logic works with LlamaIndex
- Verify that the model can use both of its existing knowledge, and our embeddings'
- Switch OpenAI’s gpt to a local open source LLM for low cost dev iteration (even if the price of gpt-3.5 is super low, I’m also interested in doing all of this with a local model)
- Improve the retrieval :
- Try different chunking strategies when processing the markdown doc files
- Add a reranking step
See you for day 3 !