This article explains how to customize a large language model for your specific needs.
There are many approaches to adapt a Large Language Model (LLM) for your data, with the goal of enhancing the responses relevance.
Prompt engineering : you spend time working on a good prompt, eventually a templated prompt where you can include your data. This is the fastest way, but will also quickly become limited, as the context size (maximum input you can give to a model) is usually in the range of 4 - 16K tokens (3 - 11K words), and it is shared between question and response. So you won’t be able to include all of your data in the prompt (or you will do so at the expense of the response length)
Fine-tuning : you can take existing models and fine-tune them with your own data. You could use openAI’s fine-tuning API (can become expensive if you don’t get it right the first time), or fine-tune an open-source model, like mistral, mixtral, llama2. This approach yields great results, but is still expensive in terms of engineering resources and computing costs, as one needs to go through model training iteration loops, harder than iterating over a prompt. More information on when to fine-tune here.
Training from scratch : this is so prohibitively expensive that only companies like OpenAI, Meta, Google can afford the 1000s of GPUs required to perform what we call the pretraining (understand basic language and concepts by learning to predict the next token)
Retrieval Augmented generation (RAG) : it is a good trade off with medium engineering complexity and costs, and high impact on the accuracy and relevance of the augmented model. In a way, it’s a bit like prompt engineering on steroids. Let’s deep dive into it and see how to make one.
RAG is a technique for enhancing the accuracy, reliability and relevance of generative AI models by giving it ultra relevant facts at query time, previously fetched from internal or external sources and vectorized as embeddings.
Here is how such a system can be built :
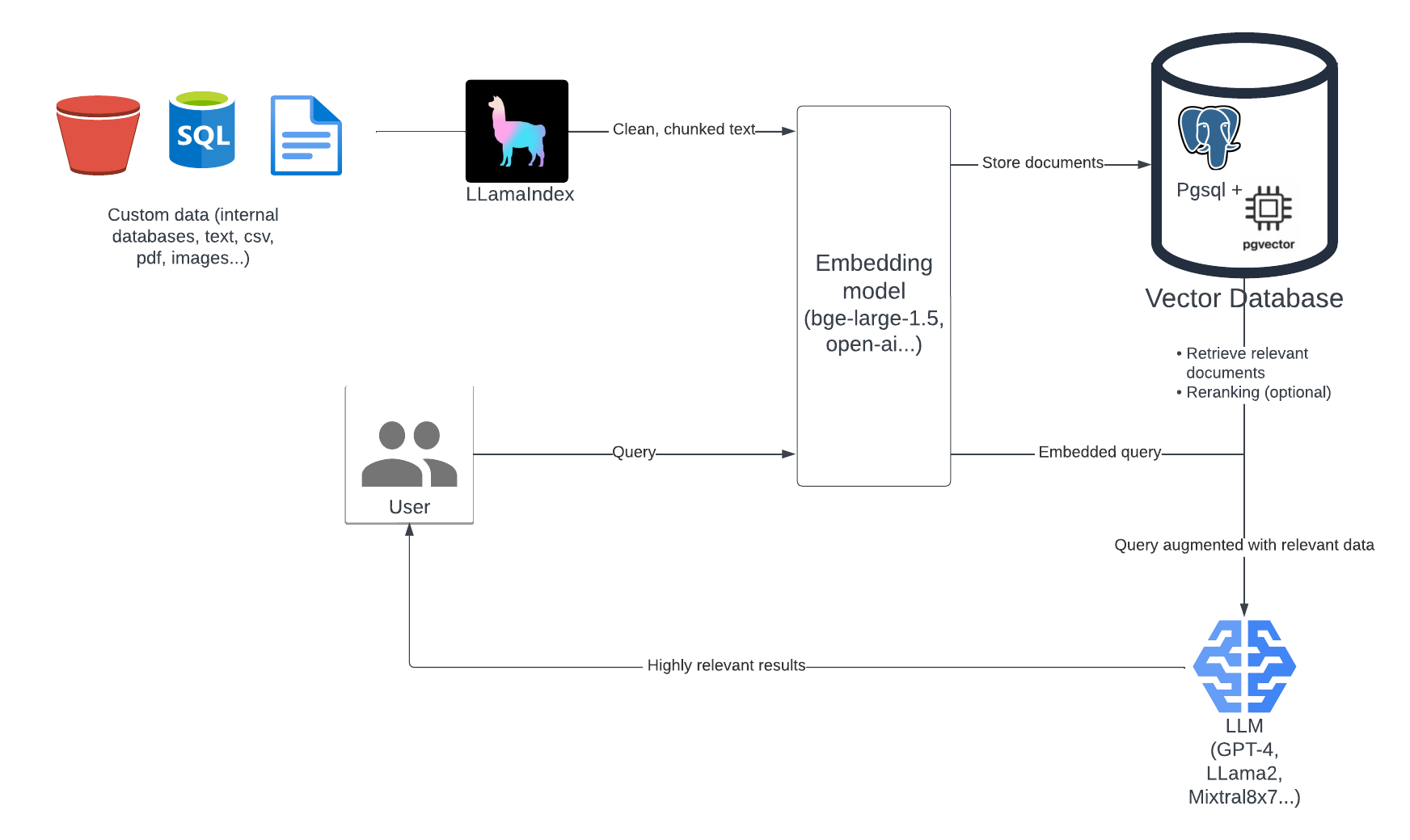
Let’s dive into building a RAG-based LLM application using publicly available data.
What we’ll cover:
- 💻 Setting up and processing workloads locally.
- 🚀 Scaling your solution to the cloud effortlessly.
- 💡 Enhancing performance with reranking, fine-tuning, and prompt engineering.
Steps
1. Get the data
Start by gathering data from public sources. For this project, we want to use web resources, this means crawling a web page (make sure the license allows it !) and collect a dataset like below.
| url | section | text |
|---|---|---|
| https://huggingface.co/docs/trl | Introduction | “Here’s how to start with LLM…” |
| https://huggingface.co/docs/trl | Getting Data | “Data is crucial for training LLMs…” |
| https://docs.metaflow.org/api/client | Training | “To train your model, begin with…” |
| … | … | … |
text should be about 1000 characters.
Future articles will delve into using internal/proprietary databases.
2. Preprocess the data
You’re probably gonna get a dirty dataset, with many lines without any content, or a very limited content. Add columns to your dataframe for the word count, to perform basic filtering and remove rows without info :
df = df[df.word_count > 15]
df = df[df.char_count > 50]
3. Transform text data to embeddings
Embeddings turn text into a numerical vectors that are understandable by LLMs.
We’ll use LLamaIndex for embedding and storing the vectors, so that’s where you select the model you want to use. We’ll use openAI’s
text-embedding-3-small which is cheap (1$ = 10K pages of text embedded) and efficient.
from llama_index import ServiceContext, set_global_service_context, VectorStoreIndex
set_global_service_context(
ServiceContext.from_defaults(llm="gpt-3.5-turbo", embed_model='text-embedding-3-small')
)
Note: While we start with embeddings only for efficiency, adding a reranking model would further refine relevance. We’ll do it as a next step
4. Store the data in a vectorDB
We’ll use pgvector for storing our embeddings. Here’s how to set it up with PostgreSQL:
CREATE EXTENSION pgvector;
CREATE TABLE document (
id serial primary key,
"text" text not null,
source text not null,
embedding vector(1024)
);
And inserting your embedded vectors :
from llama_index.indices.vector_store import VectorStoreIndex
from llama_index.vector_stores import PGVectorStore
vector_store = PGVectorStore.from_params(
database=,
host=,
password=,
port=,
user=,
table_name="document",
embed_dim=1536, # openai embedding dimension
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
df, storage_context=storage_context, show_progress=True
)
5. Perform inference
For inference, we need to :
- embed the user query (like we did for the documentation)
- use it on the vectorDB to retrieve relevant documents
- optionally rerank them with a reranker
- Compile a contextual prompt
Note : we could also use LLamaIndex for those parts
def query_vector_db(query_embedding, top_k=5):
# Query the top_k most similar vectors
cur.execute("SELECT * FROM document ORDER BY embedding <-> %s LIMIT %s", (query_embedding, top_k))
return cur.fetchall()
query = "How to fine-tune a mistral LLM with DPO ?"
query_embedding = openai.OpenAI().embeddings.create(input = query, model="text-embedding-3-small").data[0].embedding
related_documents = query_vector_db(query_embedding)
# optional : rerank here
Compile a prompt :
prompt = f"""
Answer this question using your existing knowledge and the relevant context below: ${related_documents[:3]}
If the context doesn't help you answer, prefix your message with: "Context not relevant."
If the context is empty, prefix your message with: "No context."
If you don't know the answer and the context doesn't help you, say "I don't know".
The question is : ${query}
"""
And finally send it to your LLM :
from openai import OpenAI; client = OpenAI()
stream = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
stream=True,
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Conclusion
Building a RAG-based LLM from scratch teaches you the nuts and bolts of modern NLP applications, from data preprocessing to deploying scalable solutions. This guide is just the beginning; stay tuned for more in-depth exploration of RAG and fine-tuning techniques.
TODO
- Homogenize between LlamaIndex or by hand