Navigating through the complexities of Apache Spark job optimization can be challenging. Based on recent consulting experiences with various companies, I have compiled a list of best practices for optimizing Apache Spark applications. These strategies have proven to be effective in enhancing performance and cost-efficiency.
Partitioning
- Partition wisely: It’s important to balance the size of partitions. Avoid too many small partitions (big coordination overhead) and too few large ones
(no parallelism). Utilize
.repartition()to get evenly sized partitions at the expense of a full shuffle, or.coalesce()to reduce shuffles at the risk of partition size imbalance. - Consider partitioning by key: For expensive filtering/grouping operations on specific columns (like a
dateorcountry), previously partitioning by these keys can be speed up the job, but beware of data skewness and partitions size. - Reevaluate partitions after filtering: Since filtering can alter partition sizes by reducing data volume, consider repartitioning to maintain optimal partition size.
- Partition size: Starting with the default size of 128MB is a advisable. For further optimization, aim for a partition count equal to four times the cluster’s core count (e.g., a cluster with 5 nodes and 16 cores would suggest 320 partitions). Ensure partitions are of a substantial size (tens of MBs at a minimum).
Files & formats
- Opt for efficient storage formats like Parquet or Delta over CSV, JSON, or text.
- Avoid creating small files problems, prefer fewer large files (1 GB is okay) rather than many small ones.
Coding Practices
- Shuffling is resource-intensive, as it requires serialization and deserialization, and a transfer over the network. Try to structure your operations to minimize shuffling.
- Scala users should prefer the Dataset API over RDDs, while PySpark users should stick to the DataFrame API.
- Native Functions Over UDFs: Whenever possible, use Spark’s built-in functions instead of user-defined functions (UDFs).
- Checkpointing: Use
.cache()to save computation time for reused data transformation segments.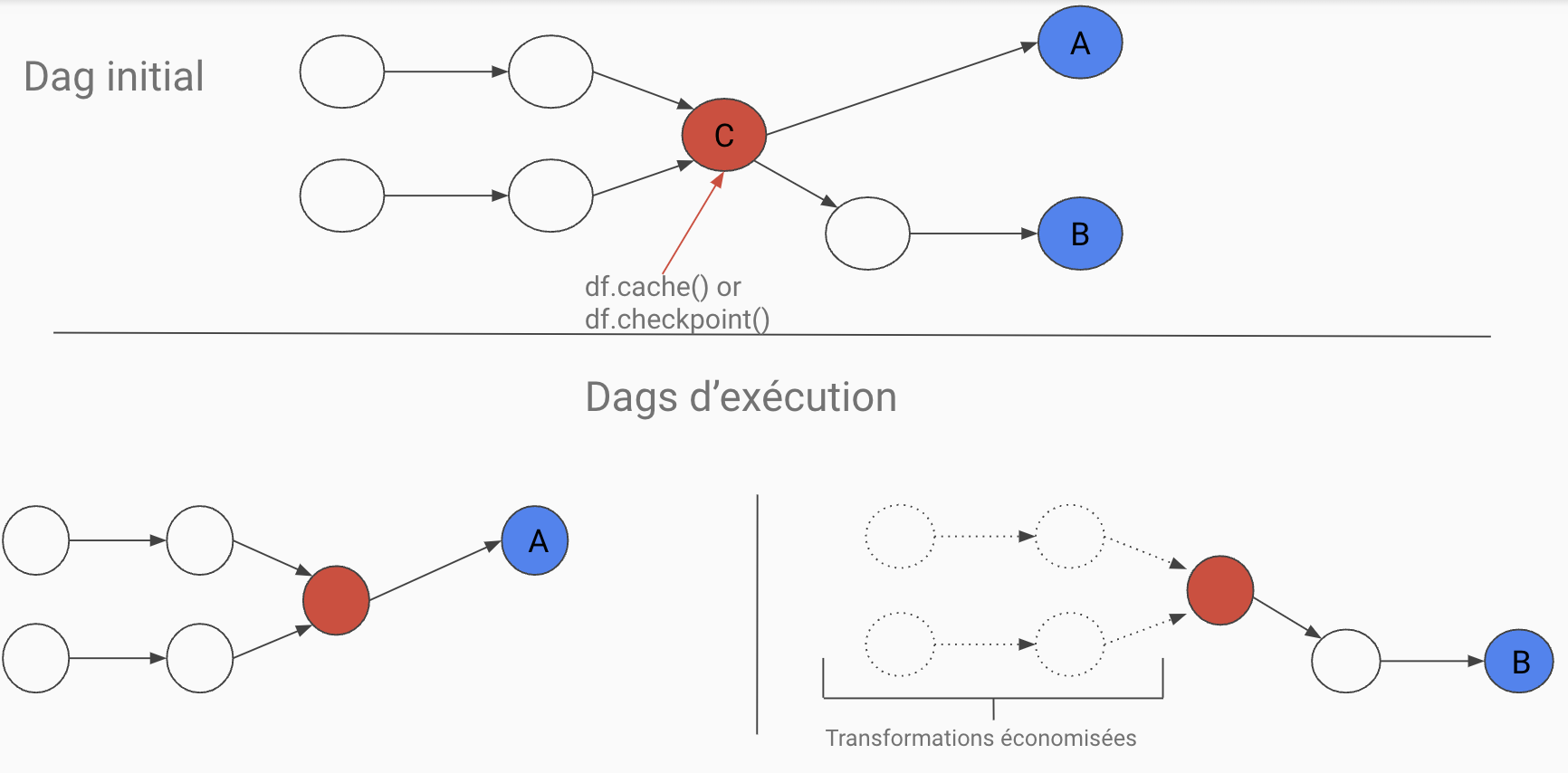
Cost Optimization
- Monitor resource: Keep an eye on hardware resources, targeting 75-80% cluster utilization for optimal cost/performance. From experience, it’s hard to have a bigger percentage, and you’ll run into OOM issues as other system processes also need resources. If you have less than that, you’re probably waisting some money.
- Leverage solutions like Elastigroup to reduce cloud expenses. They offer very cheap spot instances (less than half the real price) and use predictive rebalancing to mitigate the risks associated with spot instance interruptions.
Conclusion
Keep in mind that lots of these advices are empirical, and can work in some environments, less in others depending on many factors (cloud provider, spark versions, hardware, number and config of the nodes…).
If your spark job is critical, spend time in testing and measuring what works for you.